

Research · Systems
A Reproducible Walk-Forward Backtester
Cross-language parity, regime segmentation, and robustness stress testing for systematic trading research.
A research-grade backtester built twice: a Python reference and a specification-driven Rust port that produce numerically indistinguishable results on three deterministic configuration surfaces. When the same metric comes out of two independent implementations to within a thousandth, a measured edge is a property of the method, not an artifact of one engine. It is open source, Apache 2.0 licensed, and runs from a clean clone with no data downloads.
SSRN Working Paper
Under review, not yet posted.
Source on GitHub
github.com/DaruFinance/quant-research-framework-rs
In short
Speed
~28x faster, ~37x less memory
The Rust port runs the full default pipeline on 48,000 bars in about a quarter of a second, against roughly seven seconds for the Python reference, in single-digit megabytes of RAM.
Parity
156 / 156 within 1e-3
Re-running the three parity harnesses end to end, every deterministic-core metric point matched the Python reference at print precision (max deviation about 5e-5). The published record covers 210 points across the same surfaces.
The contribution
The bundle, not any one piece
Walk-forward optimisation, per-regime lookback tuning, strict no-look-ahead enforced at the trade ledger, and a cross-language parity record. Each exists somewhere; no other open framework ships all of it.
What this is
Most open-source backtesters give you an execution loop and leave the research discipline to you: how you split in-sample from out-of-sample, whether your indicators secretly peek at the future, and how an edge holds up once fees, slippage and funding are real. This framework moves that discipline into the engine. Walk-forward optimisation, regime segmentation, realism controls and a five-scenario robustness suite are built in, and a strict no-look-ahead invariant is enforced at the trade-ledger level so an author cannot accidentally trade on a bar that has not closed.
The same algorithmic specification is implemented twice. The Python reference is readable and easy to extend; the Rust port is built for speed. A parity harness compares their metric ledgers point by point, which is what lets the project claim its numbers are real rather than implementation lore. The figures below are generated from the framework's own runs.
How it fits together
Data flows through a shared indicator core into a strategy contract that returns one signal per bar, then through an execution core that applies every cost and the walk-forward orchestrator that re-optimises and forward-tests each window. The parity harness sits at the end, where both implementations' ledgers are expected to agree.
Walk-forward, by construction
Each iteration optimises on a rolling in-sample window and forward tests on the next out-of-sample sub-window, then advances. Nothing is scored on the data it was fit to.
What a run produces
A single backtest here is not a number, it is a dossier. One run of the bundled EMA-crossover strategy on SOL/USDT 1h emits an optimised in-sample and out-of-sample report, a Monte Carlo distribution over resampled trade sequences, a five-scenario robustness sweep, and a rolling walk-forward across eighteen windows. Everything in this section is the actual output of that run, drawn by the framework itself and shown unedited.
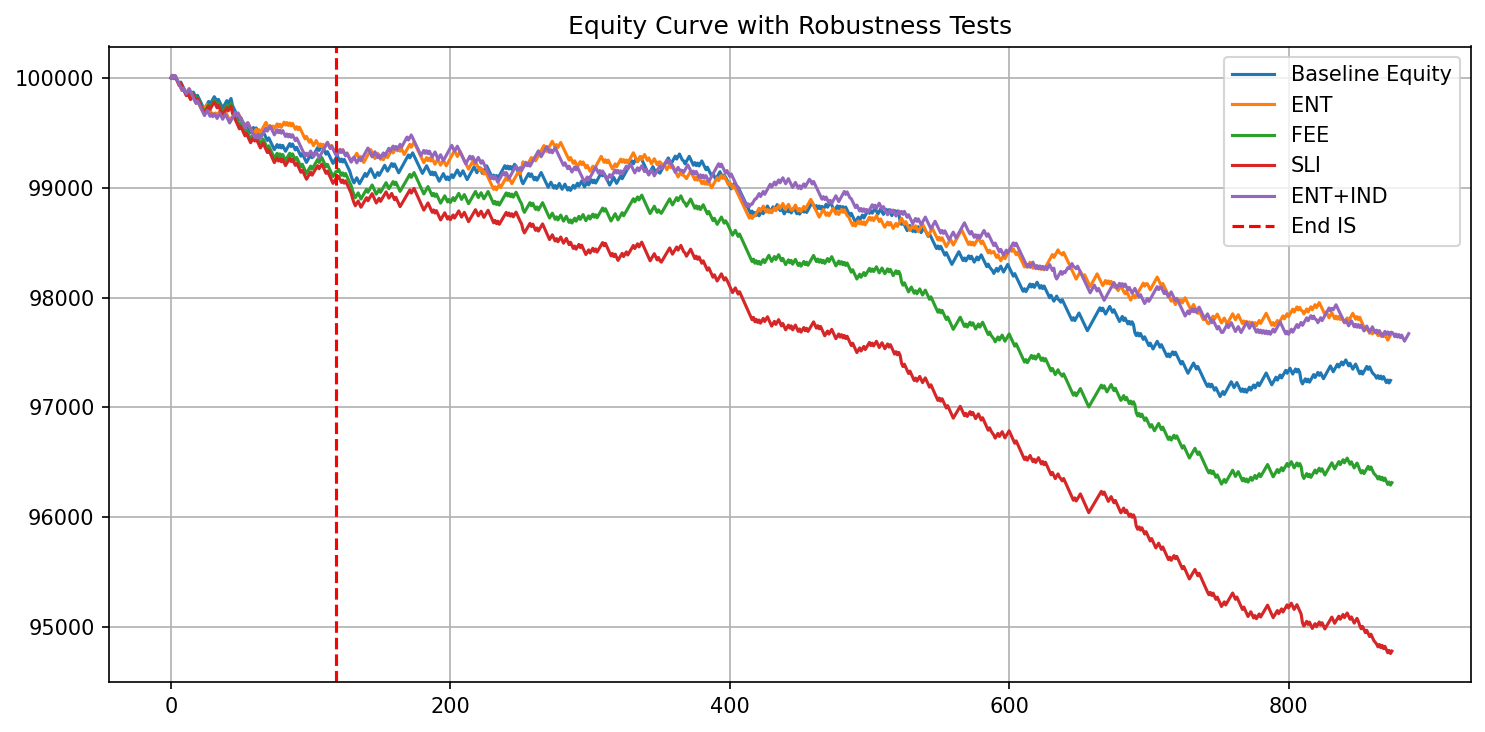
It is worth saying plainly: this strategy loses. That is the point. A bundled example that printed money would be the suspicious thing. What the framework is built to do is make a weak strategy's weakness impossible to hide, and the figures below are it doing exactly that.
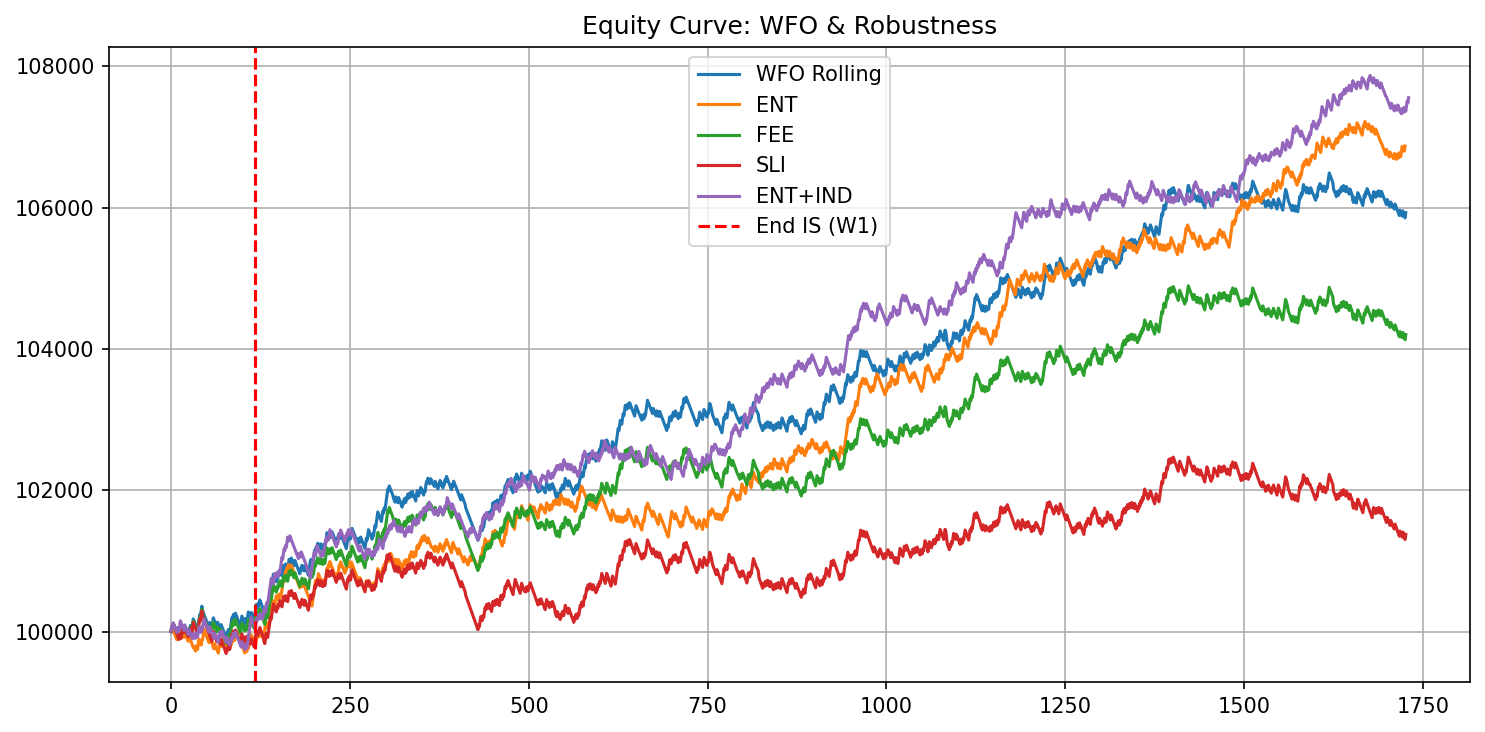
The picture flips under walk-forward. When the look-back is re-optimised on each rolling in-sample window and then forward-tested, the stitched equity actually rises. That is the trap the rest of the pipeline exists to catch: per-window re-fitting flatters almost anything, so a single rising rolling curve is not evidence of anything.
The metrics it prints
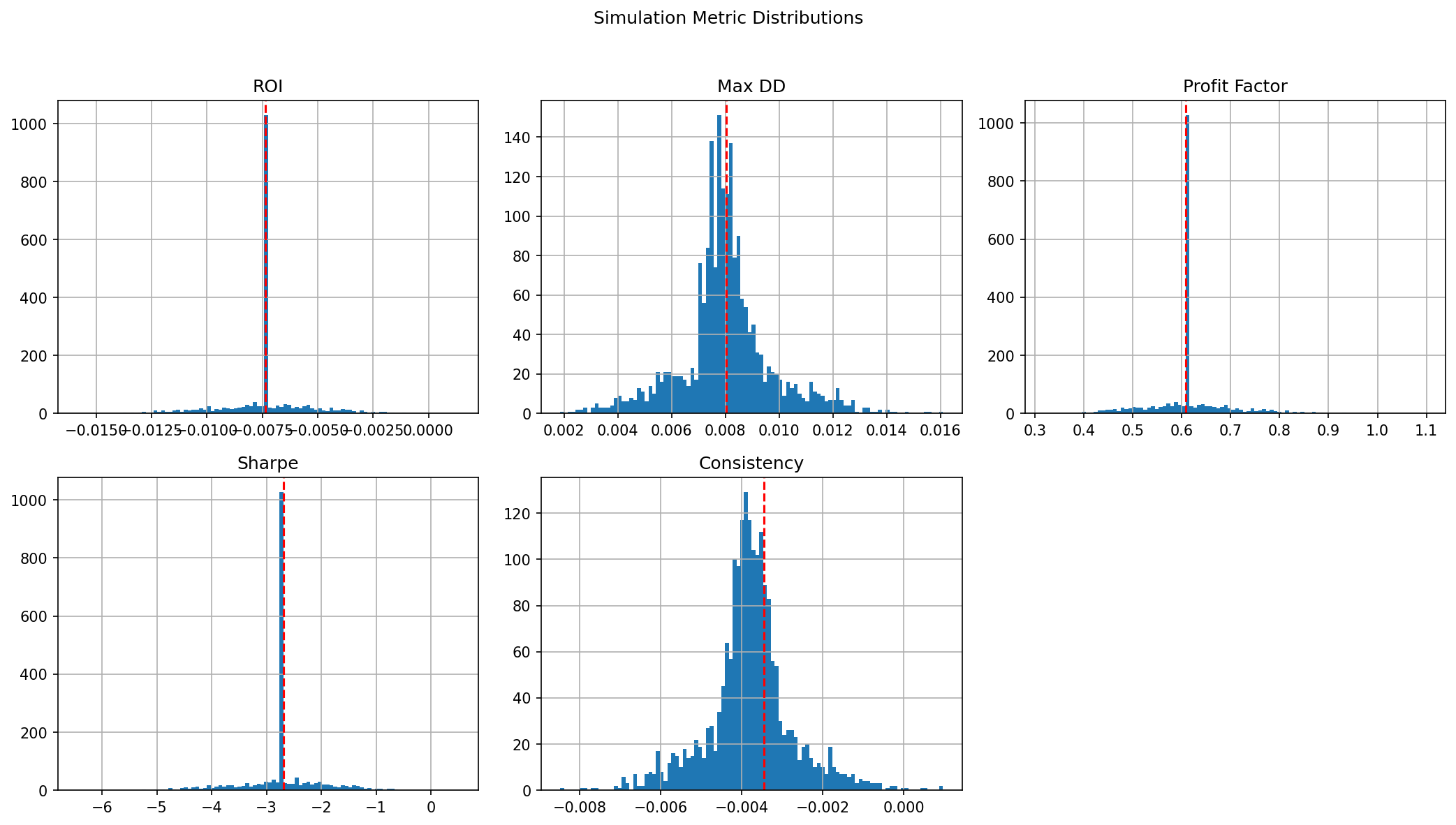
Here is what the run reports. The optimised out-of-sample Sharpe is negative, and a Monte Carlo over resampled trade orderings ends in a loss on 99.8% of paths.
IS-opt (LB 47) | Trades: 118 ROI: $-735.77 PF: 0.61 Sharpe: -2.69 MaxDD: $804.82
OOS-opt (LB 47) | Trades: 755 ROI: $-2,077.85 PF: 0.81 Sharpe: -2.91 MaxDD: $2,258.93
Monte-Carlo Percentile Ranks vs ACTUAL
ROI: 24.5th PF: 24.8th Sharpe: 74.7th
WinRate: 77.0th MaxDrawdown: 55.4th Consistency: 69.7th
Simulations ending with LOSS: 99.8%The robustness sweep re-runs the optimised baseline under four perturbations. Slippage shock is the worst case, roughly doubling the out-of-sample loss; a one-bar entry delay is nearly harmless. The spread between them is a cheap read on how fragile the result is to assumptions you cannot control.
Baseline OOS | ROI: $-2,077.85 PF: 0.81 Sharpe: -2.91 MaxDD: $2,258.93
ENT OOS | ROI: $-1,623.33 PF: 0.84 Sharpe: -2.30 MaxDD: $1,809.32 entry drift +1 bar
FEE OOS | ROI: $-2,832.73 PF: 0.74 Sharpe: -3.99 MaxDD: $2,876.37 fees x2
SLI OOS | ROI: $-4,303.79 PF: 0.64 Sharpe: -6.11 MaxDD: $4,346.15 slippage shock
ENT+IND OOS | ROI: $-1,629.68 PF: 0.85 Sharpe: -2.29 MaxDD: $1,875.23 drift + indicator jitterAnd the rolling walk-forward, window by window. Some windows are positive (W01 forward-tests to plus $899), but a strategy that only works in some windows, on re-fit look-backs, is noise that the aggregate and the deflation gate are built to expose, not an edge.
Running Walk-Forward Windows
W01 IS (LB 47) | Trades: 118 ROI: $308.25 PF: 1.14 Sharpe: 0.63 MaxDD: $448.35
W01 OOS (LB 47) | Trades: 92 ROI: $899.57 PF: 1.57 Sharpe: 1.95 MaxDD: $243.77
... W02 through W18 each re-optimise on the rolling in-sample window
and forward-test the next window on data they never saw ...Was it luck?
The Monte Carlo view resamples the trade sequence thousands of times and re-scores each metric, so you can see where the real result sits in the distribution of what randomness alone produces. When the actual value lands in the middle of a distribution centred on nothing, the result is indistinguishable from chance.
Performance
Both implementations run the identical default pipeline on slices of the same bundled dataset. The Rust port is roughly twenty-five to sixty times faster and holds peak memory about thirty-seven times lower, single-threaded.
Cross-language parity
Speed is worthless if the fast engine is wrong. Re-running the three parity surfaces end to end, every deterministic-core metric point agreed with the Python reference within a thousandth. Two sections are intentionally non-deterministic by design and are excluded honestly, not hidden.
How it compares
Plenty of mature backtesters exist, and each capability here lives somewhere already. The point is the combination, and that it is enforced rather than left to convention.
What is built in
Clone it and see for yourself
Every step below runs from a clean clone with the bundled sample data, no downloads and no manual setup. The numbers are from a cold run on a laptop-class machine.
One thing to expect: the bundled strategies are simple demonstrations of the pipeline, not edges to trade. Run honestly out of sample with real costs, they are meant to lose. That is the framework exposing a weak strategy rather than flattering it, which is the whole point of evaluating this way.
Citation
The accompanying paper is under review at SSRN. A formal link will appear here once it is posted. In the meantime, the framework is citable from its repository.
See also
Within-strategy permutation testing for the selection method this backtester is built to support, and the Research Review for from-scratch reproductions that lean on exactly this kind of walk-forward, deflation-aware evaluation.